進行資料探勘時,往往最耗時的步驟並不是對資料進行演算,而是取得資料和處理資料。若沒有合適的資料做為 input,最後只會落得 garbage in, garbage out 的下場。近年來,開放資料的風氣盛行,政府和民間都陸續將所蒐集到的資料釋出,例如 data.taipei 等,成為資料科學家們取得資料相當方便的來源。但絕大多數的資料並不在這類型的網站上,等著人下載,若能學會基本的網路爬蟲方法,則能將網路上別人的資料變成自己的資料,加以運用。
製作網路爬蟲的基本原理分為三個階段,分別是網頁擷取、網頁解析、存取入資料庫。本篇以 Python 3 示範前兩個取得資料的步驟,所使用的套件 requests 和 BeautifulSoup4 可以透過 pip 來安裝。
一、Setup
安裝網頁擷取套件 requests
pip install requests
安裝網頁解析套件 BeautifulSoup4
pip install beautifulsoup4
在 Python 環境中使用這兩個套件
import requests from bs4 import BeautifulSoup
二、網頁擷取
完成了基本的 setup 之後,建議到想要爬取的網站根目錄下的 robots.txt 查看,並確保資料的爬取合乎該網站的使用規範。
使用 GET 方法取得網頁資料
res = requests.get(“http://example.com”) print(res.text)
使用 POST 方法取得網頁資料
payload = {
‘Some sample’:’Data Content’,
‘Some sample’:’Data Content’,
}
res = requests.post(“http://example.com”, data = payload)
print(res.text)
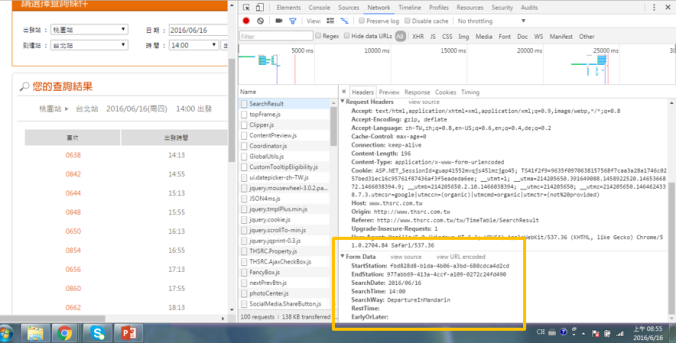
我們在 payload 這個變數當中以 dictionary 的形式存入我們要 input 的資料,以查詢高鐵乘車時刻為例,我們可以對網頁「點擊右鍵 > 檢查 > Network 」(Chrome),接著在網頁中輸入資料按下查詢,點選檢查視窗中的第一個結果,拉到最下方即可找到變數的名稱和內容。
三、對所取得的網頁資料進行解析
soup = BeautifulSoup(res.text) print(item.select(‘.item’)[0].text)
這裡的 item 為我們想擷取的資料的 class name,順道介紹 SelectorGadget 這個 Chrome 擴充套件,它可以幫我們快速找到資料對應的 class name。
所擷取下來的資料是一個 list 的形式,如果符合 class name的資料有多筆,則會依序存入這個 list,因此上述的[0] 代表的是list中的第一筆,實際應用上我們常會搭配迴圈來將多筆資料一次存取。.text 這個 method 則可以幫助我們取得不含 html 標籤的純文字內容。
能夠成功 print 出想抓取的資料內容,就已經完成一個最基本的網頁爬蟲了。
